Con motivo de la evaluación del Concurso Universitario de Software Libre, esta última semana he estado trabajando en montar una versión de LibreBorme en producción y en darle una capa de pintura.
Para los impacientes: ya se puede acceder a través de https://beta.libreborme.net https://libreborme.net.
Como su dominio indica, es una versión de pruebas, por lo que fallará de vez en cuando, sus URLs cambiarán, algunas veces contendrá más datos y otras menos porque limpiaré la BD para seguir haciendo pruebas... Tenlo en cuenta si la usas. De momento no hace falta que se reporten los bugs.
Funcionalidades actuales
En cuanto a cambios significativos lo más novedoso es que gracias a la sugerencia de mi tutor del proyecto, he empezado a usar MongoDB para almacenar los datos, que viene muy bien ya que la estructura de un BORME se ajusta más al concepto de documento en Mongo que al de una tabla relacional SQL.
En esta primera versión online ya hay algunos miles de datos para empezar a jugar. Se pueden buscar empresas, ver en qué BORMEs aparece y sus actos mercantiles. También es posible buscar nombres de persona y de la misma manera localizar en qué BORMEs aparece y obtener un listado de sociedades relacionadas.
La página principal se carga cada vez con un listado aleatorio de empresas/personas a modo de ejemplo:
Ahora borme_parser es un paquete que importo en Python y que contiene todo lo necesario para procesar BORMEs. Cuando sea estable lo subiré a PyPI para que lo puedan reutilizar fácilmente otros proyectos que analicen BORMEs.
También he comenzado a usar los issues de GitHub:
borme_parser
El paquete borme_parser contiene un conjunto de herramientas que automatiza la obtención y el procesamiento de BORMEs. El proceso ahora es semi-automático (hay que lanzar los scripts uno a uno).
Los procesos que borme_parser automatiza son:
- Ir a la web del BORME y obtener los BORMES del último día
- Descargar todos los PDFs del día
- Recortar los PDFs para obtener otros PDFs con la región que nos interesa (quita los márgenes)
- Conversión de PDF a texto y limpieza del texto que suele contener caracteres extraños
- Reconocer en el texto los actos inscritos y en ellos los nombres de las entidades que nos interesan (empresas y personas principalmente) y generar un archivo CSV a partir de ellos
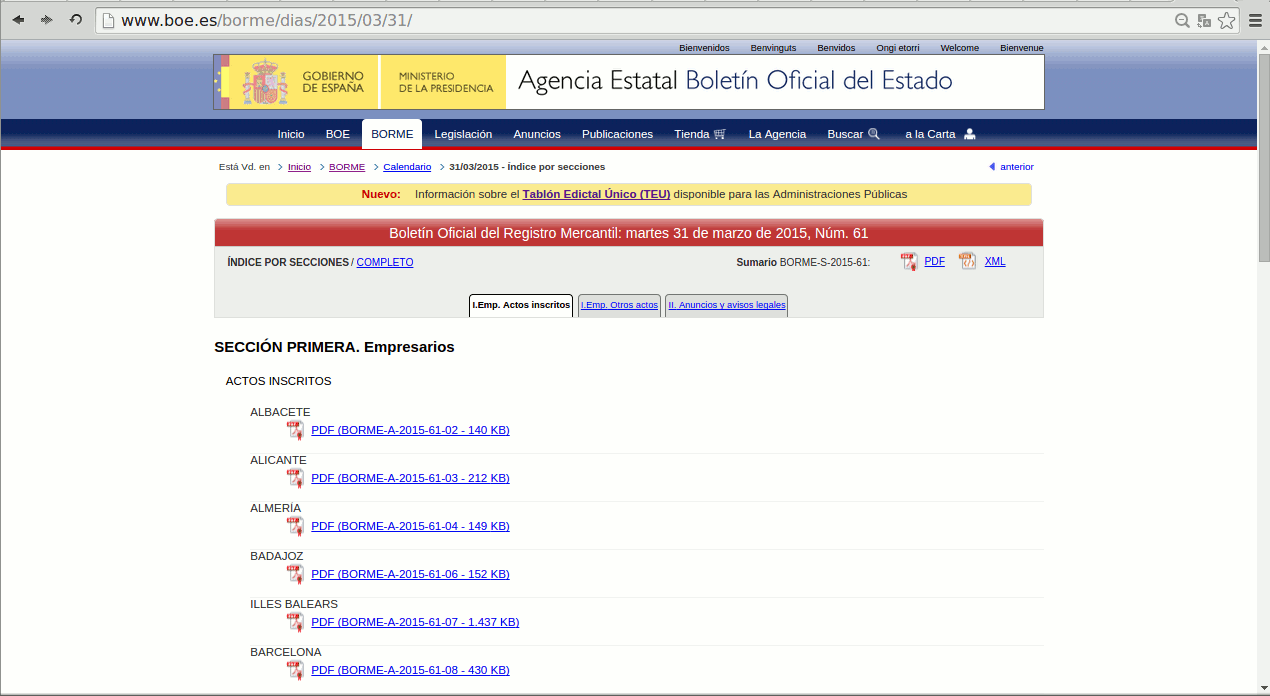
Para el que lo nunca haya visto, un BORME tiene el siguiente aspecto:

Detalles técnicos: para recortar PDFs uso PyPDF y para convertir los PDFs recortados a texto uso pdfminer. ¿Por qué dos distintos? Porque cada uno me ha dado mejores resultados en esa tarea concreta.
Para las otras dos secciones del BORME que sí publican en XML, la idea es usar XML Schema para que los parsers sean más flexibles y tolerantes a futuros cambios en la estructura.
Como anécdota, para pulir el parser me hice un script para comparar los resultados de dos parsers y ver así si los últimos cambios realmente mejoraban o empeoraban el resultado esperado.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #!/bin/bash
# ./parseandcompare.sh txt2/BORME-A-2015-27-07.pdf-cropped.pdf.1.txt.clean.txt
echo $1
./parserText2CSV4c.py $1
csv4=csv/$(basename $1).4c.plain
diff -u0 $2 $csv4|pygmentize -l diff -f html -O full -o file_diff14.html
echo 'Comparando'
echo $2
echo $csv4
ls -l $2 $csv4
chromium-browser ./file_diff14.html &
|
Esto genera un archivo html con las diferencias así:
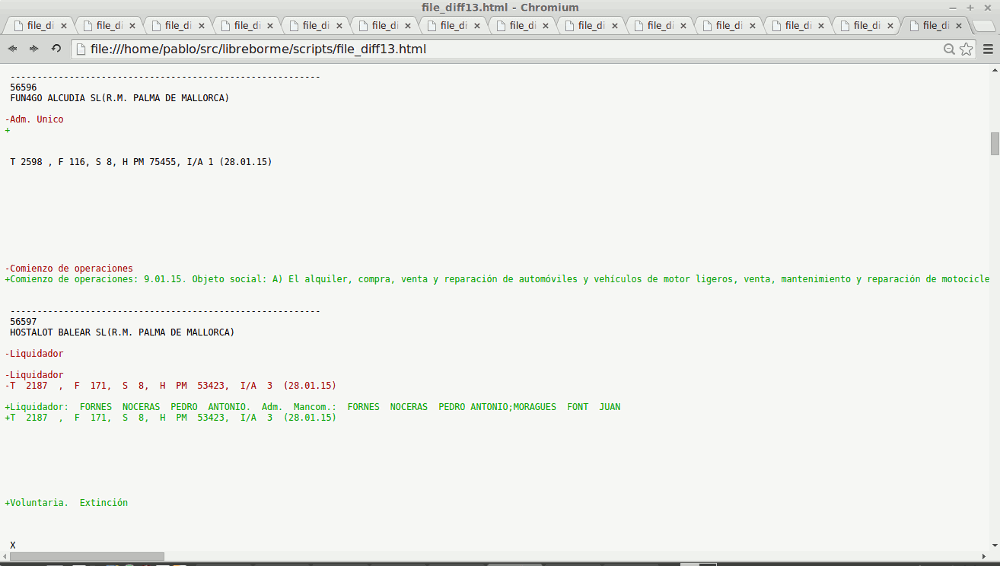
En definitiva, los parsers funcionan, aunque tienen aún fallos y queda pulirlos bien. Tengo muchas ideas que quiero probar para mejorarlos. Más adelante dedicaré una entrada solo para ellos.
Datos importados
En esta beta he cargado los datos disponibles hasta el 24 de marzo de 2015.
Algunos datos a modo de estadística:
Los PDF de la Sección Primera descargados (hasta el 24 de marzo) son en total 1609 archivos que pesan 372MB. Una vez recortados pesan 245MB y pasados a texto y aplicando el filtro de limpieza de caracteres raros, ya se quedan 52MB y finalmente los datos útiles en CSV son 40MB.
Importar los datos de 2015 en LibreBorme fue «tan sencillo» como ejecutar:
cd borme_parser
./getAllBormeXML.py 20150101
./getPDFfromXML.py 20150101
./crop_borme.py pdf
./parserPDF.py pdfcrop
./cleanText.py txt
./parserText2CSV4c.py txt2
./manage.py importbormecsv borme_parser/csv/*.csv
Algunos tiempos de cada script, en negrita los más significativos:
Conversión de PDF a texto: 44 minutos Limpieza del texto: 3 segundos Generación de los CSV a partir de los textos: 29 segundos Importación en Mongo: más de 8 horas
El proceso de importación de estos 40MB de CSV tardó más de 8 horas, algo que sin saber apenas nada de Mongo me parece excesivo y que tendré que investigar. Lo más lógico sería generar e importar directamente JSON en lugar de CSV, pero el motivo de porqué uso CSV es porque fue lo primero que se me ocurrió cuando aún no sabía que iba a usar MongoDB.
En total se han incorporado a la base de datos 124168 registros, identificándose 104800 empresas y 34496 personas.
Sin embargo a día 24 de marzo había 124879 registros, por lo que en 711 (0,57%) el parser falló y no consiguió importarlos.
¡Seguimos!
Comments !